1. Introduction
机器学习主要分为三类:监督学习、无监督学习和强化学习。
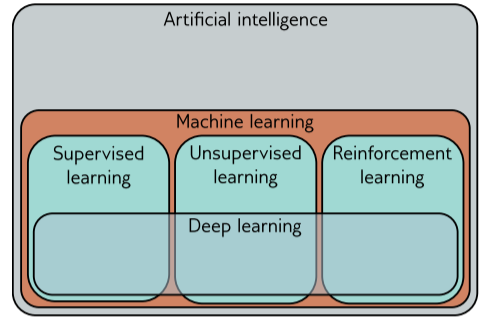
1.1 Supervised learning(监督学习)
监督学习通过建立从输入空间 $X$ 到输出空间 $Y$ 的映射函数:
$$
f_\theta: X \to Y
$$
其中:
- $D={(x_i,y_i)}_{i=1}^n$ 是训练数据集
- $x_i \in X$ 是输入特征向量
- $y_i \in Y$ 是监督信号(ground truth)
- $\theta$ 是模型参数
通过优化算法最小化损失函数 $\mathcal{L}(\theta)$ 来学习参数:
$$
\theta^* = argmin_{\theta} E_{(x,y)\sim D}[L(f_\theta(x), y)]
$$
1.1.1 回归问题和分类问题
以房地产价格预测任务为例,定义输入特征向量 $x$=[地理位置,建筑面积,设施评分,… ],输出变量 y 根据任务类型分为以下两类:
- 回归问题:
- 输出空间:连续值标量或向量$(Y⊆R^d)$。
- 示例:
- 单变量回归(Univariate Regression):$y=[房价(万元)]∈R$。
- 多变量回归(Multivariate Regression):$y=[房价,年涨跌幅]∈R^2$
- 分类问题
- 输出空间:离散类别标签(YY 为有限集合)。
- 示例:
- 二分类(Binary Classification):$y∈{0,1}$,例如 1 表示“一年内成交”,0 表示“未成交”。
- 多分类(Multiclass Classification):$y∈{1,2,…,K}$,例如 ${1,2,3}$ 分别对应“1年内/2年内/3年以上成交”
1.1.2 机器学习模型:
基础理解
可以把机器学习模型看作一个超级升级版的线性回归方程:
传统线性回归
y = ax + b(2个参数)机器学习模型
输出 = 复杂函数(输入)(可能含上亿参数)
核心特点
函数复杂度
- 不再是简单直线
- 包含多层非线性计算
参数量级
模型类型 参数量级示例 简单模型 几百~几千 深度神经网络 百万~十亿级 大语言模型 百亿~万亿级 学习方式
通过大量数据自动调整参数,而非人工设定公式
1.2 Unsupervised learning(无监督学习)
无监督学习是让机器直接从没有标注的数据中自动发现规律的方法
核心特点
▸ 只有输入数据,没有标准答案
▸ 机器自主发现隐藏结构
▸ 不需要人工标注(省时省力)
1.2.1 生成式模型
生成式无监督模型的目标是学习训练数据的统计规律,从而能够合成与原始数据相似的新数据样本。例如,用人脸图片训练后,模型可以生成不存在但逼真的人脸。主要有两种:
- 显式概率分布模型:
这类模型(如VAE、自回归模型)直接建模数据的概率分布(即明确知道数据出现的概率公式)。生成新样本时,通过从学到的分布中随机采样实现。例子:若训练数据是手写数字,模型会学习每个像素值的概率分布,采样时像”抛硬币”一样按概率生成像素。 - 隐式生成模型:
这类模型(如GAN)不显式定义数据分布,而是通过复杂的映射机制(如神经网络)直接生成样本。虽然结果与训练数据相似,但无法直接获取概率公式。
例子:GAN的生成器像一位”仿造大师”,它通过不断调整参数输出逼真样本,但不会告诉你某个样本的具体概率。生成式模型本质上只是基于语言统计规律的最可能续写,而非真正的理解。
例子:若提问”太阳系的行星有哪些?”,模型会从训练数据中统计出高频答案(如”水星、金星…”),但并不知道这些名词的物理意义。
{.is-warning}
1.2.2 潜在变量
- 核心背景:数据的低维本质
现象:真实数据(如自然语言、图像)的有效范围远小于原始观测空间。
- 例子:
- 有意义的句子 ≪ 随机词串的组合。
- 真实图像 ≪ 随机RGB像素的排列。
- 例子:
原因:数据受物理规律或语义规则约束(如语法、物体结构)。
- 关键方法:潜在变量(Latent Variables)
- 定义:用少量隐含变量捕捉数据的本质特征。
- 设计原则:
- 潜在空间通常设计为简单分布(如高斯分布),便于采样。
- 深度学习模型作为“解码器”,将潜在变量映射到复杂数据空间(如图像、文本)。
- 生成新数据的流程
1.采样:从潜在变量的分布中随机采样(如正态分布)。- 映射:通过训练好的模型将采样点转换为数据空间的样本。
- 输出:生成符合真实数据规律的新样本(如逼真图像)。
- 实际应用:基于潜在变量的数据操控
- 插值(Interpolation):
- 步骤:
- 将两个真实数据编码为潜在变量。
- 在潜在空间中对它们线性插值。
- 解码插值点,生成过渡序列(如表情渐变图像)。
- 步骤:
1.2.3 监督学习和无监督学习的联系
背景
- 在监督学习中,当输出具有结构时,如根据文本描述(caption)来预测对应图像的任务,直接将文本输入映射到图像可能会面临一些问题。
带潜在变量生成模型的应用及优势
- 应用方式:不是直接从文本映射到图像,而是学习解释文本的潜在变量与解释图像的潜在变量之间的关系。
- 优势:
- 数据需求降低:由于输入和输出都降到了低维的潜在变量空间,可能需要更少的文本/图像对来学习这种映射关系。
- 生成图像更合理:潜在变量空间中的合理值通常能生成看起来合理的图像,使得生成的图像更有可能是符合常识的示例。
- 可生成多样性图像:如果在潜在变量之间的映射或从潜在变量到图像的映射中引入随机性,就可以生成多个都能很好地被该文本描述所描述的图像,增加了生成结果的多样性。
1.3 Reforcement learning(强化学习)
强化学习(Reinforcement Learning, RL)是机器学习的一个分支,其核心是让智能体(Agent)通过与环境交互学习最优决策策略。
1. 核心概念
- 智能体(Agent):学习者与决策者
- 环境(Environment):智能体交互的世界
- 状态(State):环境的当前情况
- 动作(Action):智能体的行为选择
- 奖励(Reward):环境给出的即时反馈
2. 关键特性
- 时间信用分配问题:
- 奖励可能延迟出现
- 需要确定哪些动作导致了最终奖励
- 探索-利用困境:
- 利用已知最优策略 vs 探索可能更好的策略
3. 主要方法
| 方法类型 | 代表算法 | 适用场景 |
|---|---|---|
| 基于价值 | Q-Learning, DQN | 离散动作空间 |
| 基于策略 | Policy Gradients, PPO | 连续动作空间 |
| 混合方法 | Actor-Critic | 复杂环境 |
1.3.1 两个例子
一、时间信用分配问题(Temporal Credit Assignment)
- 示例 1:机器人行走(Locomotion)
- 任务:通过控制关节移动完成障碍物路线。
- 奖励:到达检查点时获得奖励。
- 问题:难以判断哪些动作导致最终的奖励,哪些无关。
- 示例 2:国际象棋(Chess)
- 任务:学习下棋策略。
- 奖励:
- 方式一:吃子获得中间奖励;- 方式二:仅在胜利时给予最终奖励。
- 问题:系统难以分辨哪些走法对胜利有决定性作用。
二、探索-利用权衡(Exploration vs. Exploitation)
示例 1:机器人行走
- 已知策略:躺着滑行,速度慢但可获得奖励。
- 最优策略:站立行走,尚未探索。
- 面临选择:继续使用低效但可行的方法,或探索可能更优的方案。
示例 2:国际象棋
- 已知策略:一套合理的开局走法。
- 面临选择:利用已有开局,还是探索新的可能性?
三、深度学习在强化学习中的应用
- 使用深度神经网络将“状态”映射为“动作”。
- 称为策略网络(Policy Network)。
- 应用实例:
- 机器人:传感器输入 → 关节动作输出。
- 象棋:棋盘状态 → 落子决策。