1 类型分类
- 文档数量:单文档 vs 多文档
- 问题复杂度:简单事实性 vs 复杂叙述型
- 模态:纯文本 vs 视觉QA
- 数据源: 基于信息检索 vs 基于知识库
2 IR-based QA
基于信息检索的问答系统,对于Factoid QA(事实型问答)的流程
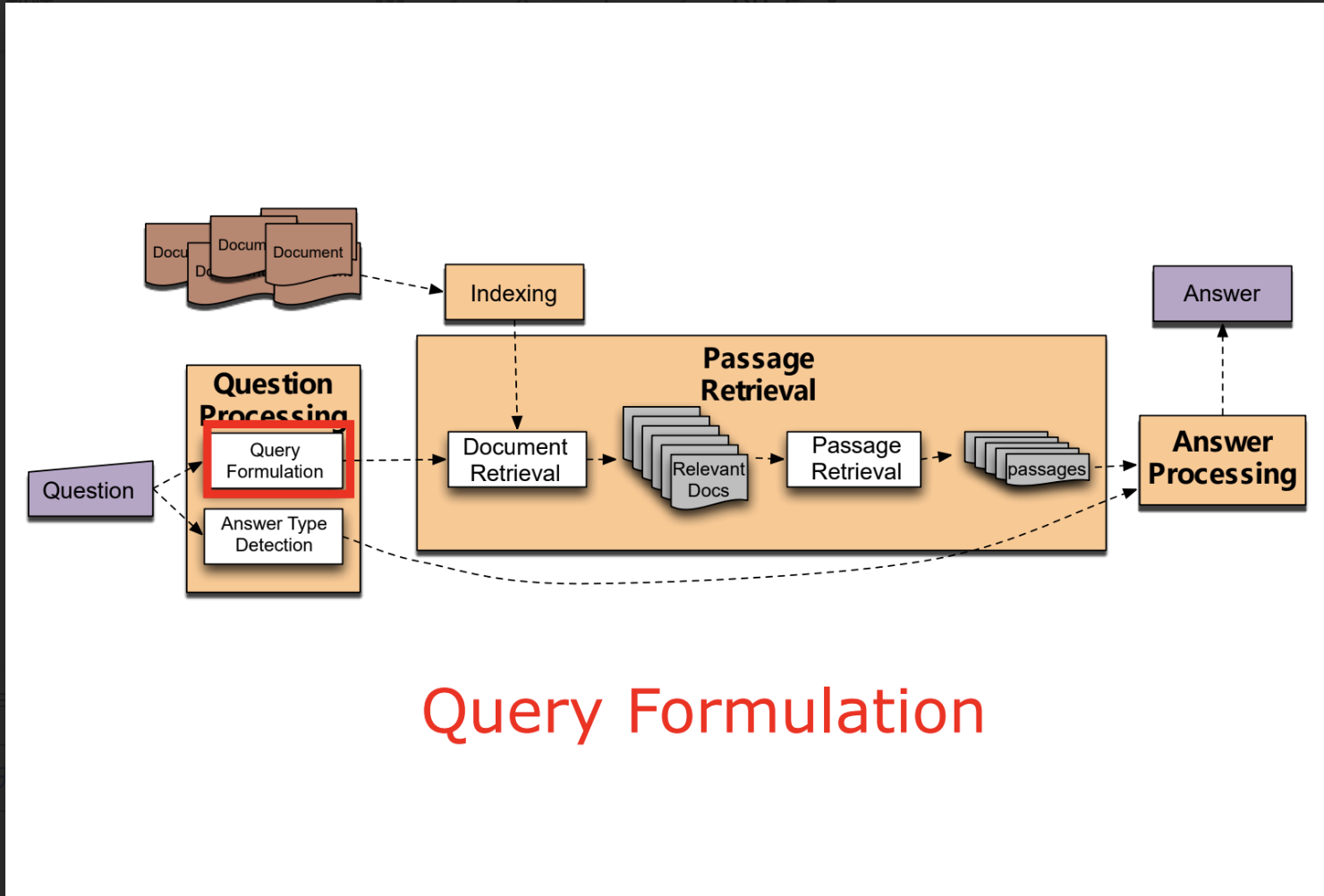
- 核心框架:
- 问题处理
- 答案类型检测:判断答案的实体类型(如人名、地点、数字)。介绍了Li & Roth的分类体系(6个大类,50个小类)。方法包括正则表达式、人工规则和机器学习分类。
- 查询构建:提取关键词,去除停用词
- 文档与段落检索
- IR基础:介绍TF-IDF权重、倒排索引、向量空间模型和余弦相似度
- 流程:先检索endangered,再将文档切分为段落,利用答案类型、关键词密度等对答案进行重排序
- 答案处理
- 候选答案提取:在选定段落中运行命名实体识别(NER),提取符合答案类型的实体。
- 答案排序:利用多种特征(如答案类型匹配、模式匹配、关键词距离、标点位置等)对候选答案打分。IBM Watson使用了超过50种组件进行评分。
- 问题处理
- 评估指标
- 准确率
- 平均倒数排名(MRR):衡量第一个正确答案在推荐列表中的排名情况
3 Knowledge-based QA
- 核心思想:将自然语言转化为对结构化数据的查询
- 资源:利用Yago,DBpedia等知识图谱或RDF三元组
- 关键技术:
- 实体链接:将文本中的提及(Mention)映射到知识库中的真实实体
- 关系抽取:识别问题中的关系
3.1 Entity Link
End-to-End
将NER和Link在同一个模型中联合完成
Link-Only
- 候选实体生成
- 实体消歧
- Feature
- Method
- 空值预测