1.知识表示
知识表示是计算机用一种表示方法来表达人类语言,或者计算机可以理解这种表示方法并在知识图谱中表达出来。
1.1. 语义网络
一个知识表示的网络结构包括 nodes 和 links(betwwen nodes)
- node: objects or concepts
- links: relations between nodes
一个网络知识图谱会用人类的语言来定义nodes和links,还会使用一些广泛接受的知识表示格式。
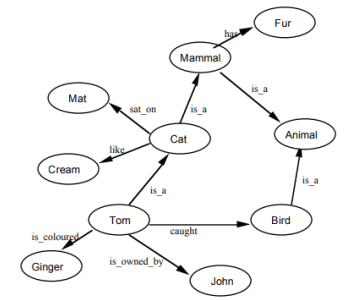
1.2. 框架结构
- 每个框架都有多个槽(slot),信息都保存在slot里面
- slot里面包含着多种多样的信息,例如 Facts or Data, Procedures, Default Values, even other frames.
一个ALex Frame 的示例
| Slot (槽) | Value (值) | Type (类型) & 说明 |
|---|---|---|
| ALEX | - | (This Frame) 框架自身的标识。 |
| NAME | Alex | (key value) 这是一个关键值,是具体的数据。 |
| ISA | Boy | (parent frame) ISA 关系表示“是一个”,说明 ALEX 是 “Boy” 框架的一个实例。这意味着 ALEX 可以从 “Boy” 框架继承属性。 |
| SEX | Male | (inheritance value) 这个“雄性”的属性很可能是从父框架 “Boy” 继承而来的默认值。 |
| AGE | IF-NEEDED: Subtract(…) | (procedural attachment) 如上文所述,这是一个程序附件,年龄是动态计算出来的,而不是静态存储的。 |
| HOME | 100 Main St. | (instance value) 关于 ALEX 这个实例的具体信息。 |
| BIRTHDATE | 8/4/2000 | (instance value) 实例的具体信息,用于 AGE 的计算。 |
| FAVORITE_FOOD | Spaghetti | (instance value) 实例的具体信息。 |
| CLIMBS | Trees | (instance value) 实例的具体信息。 |
| BODY_TYPE | Wiry | (instance value) 实例的具体信息。 |
| NUM_LEGS | 1 | (exception) 这是个例外值。通常从 “Boy” 框架继承的腿数量应该是2,但这里 ALEX 只有1条腿,覆盖了父框架的默认值。这展示了框架表示法的灵活性,能够处理特例。 |
2. 知识图谱表示
知识图谱主要有三种表达方法:XML、RDF、RDFS,OWL
2.1 XML
XML是一种用于描述结构化信息的语言,从SGML(例如HTML)发展而来,下面是一个HTML的示例:
1 | <i>This book</i> has the title <b>KG</b> |
This book has the title KG
XML vs. HTML
| 特性 | XML (可扩展标记语言) | HTML (超文本标记语言) |
|---|---|---|
| 标签 (Tags) | 可扩展的标签集 (用户可自定义) | 固定的标签集 (预定义的) |
| 导向 | 面向内容 (描述数据是什么) | 面向表示 (描述数据如何显示) |
| 数据能力 | 标准的数据基础架构 | 无数据验证能力 |
| 输出形式 | 允许多种输出形式 | 单一的表示形式 (主要用于浏览器) |
2.1.1 XML 语法
- XML 文档都是一个text 文档
- 每个XML文档开头都有如下声明:
- XML版本标准
- (可选)编码方式,默认Unicode
1 | 例如: |
- XML 元素
- 描述的对象必须包含在一个匹配的标签对中。这些标签是 case-sensitive:<CITY> <City> <city>
- 元素内部可以包含纯文本文件,也可以是其他的XML元素,嵌套是任意深度的。
- 空元素可以写成一个闭合标签: <year> </year> = <year/>
- 有且只有一个root element, 整个XML文档就是一个root element
1 | <author> |
line 1: start tag
line 2-4: sub-element
line 5: text(optional)
line 6: end tag
- XML 属性
我们可以将一个子元素转化为属性存储:
1 | <author email=“gqi@seu.edu.cn”> |
属性:email, 值:‘gqi@seu.edu.cn‘


Exercise
根据上面的规则找出下面的错误
1 | <book> |
- XML 评论
1 | 例:<!-- comment is written here--> |
- XML预定义的实体
为了防止一些符号和语法发生冲突,对于特定的符号进行预定义
| 实体 (Entity) | 代表的字符 | 说明 |
|---|---|---|
& |
& | Ampersand (和号) |
< |
< | Less Than (小于号) |
> |
> | Greater Than (大于号) |
' |
‘ | Apostrophe (单引号) |
" |
“ | Quotation mark (双引号) |
我们希望显示<html>的代码,但是XML会将<html> <head> 解析为XML结构的一部分。

使用 CDATA → <![CDATA[ … ]]>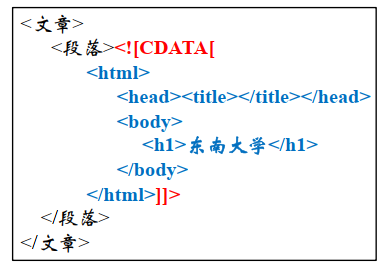
2.1.2 XML 命名空间
2.1.3 XML 规范
Why we need?
- 可以在不同应用之间使用XML文档
- XML规范使用的是 W3C 标准,规则本身也是用XML文件编写
- XML 规范必须 Well Formed(格式良好) and Valid(有效)
W3C Recommended XML Schema Language:
XML Schema Definition (XSD), https://www.w3.org/2001/XMLSchema#
1 |
|
1 | ... |
2.2 RDF
RDF: 一个三元组的数据模型 (subject, predicate,Object) 。 例如:(SEU, locateAt, Nanjing)。
一个RDF的知识库:一个有向的标记图( 知识图谱)
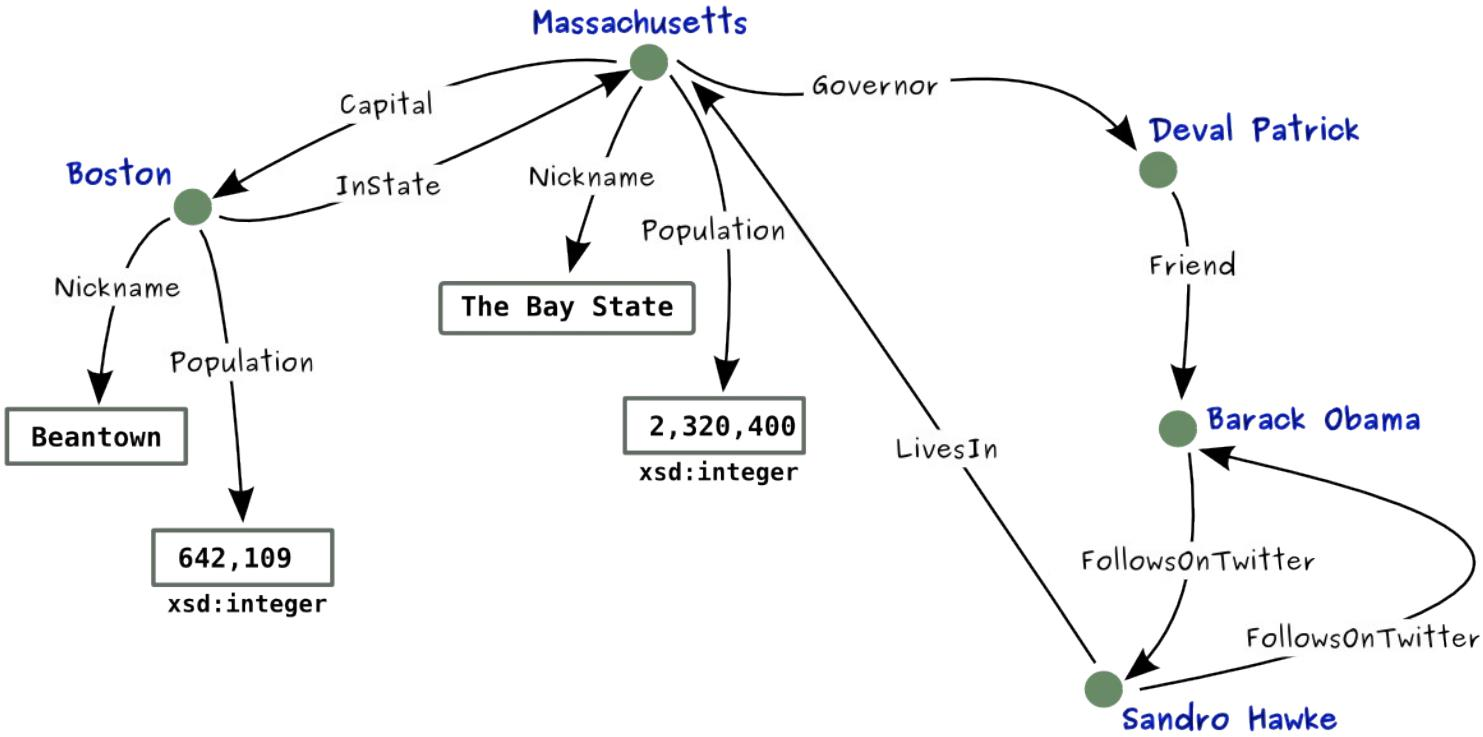
问题:names are ambiguous?
- How many things are named “Boston”?
- What is meant by “Nickname”?
We need unambiguous identifiers, such as IRI, URI,URL on the Web.
2.2.1 RDF: QName
QName: 一种用来简化和缩短URI(IRI)的书写方式
例:
If
前缀 foo 绑定到 “http://example.com/“
then:
foo:bar
expands to
http://example.com/bar
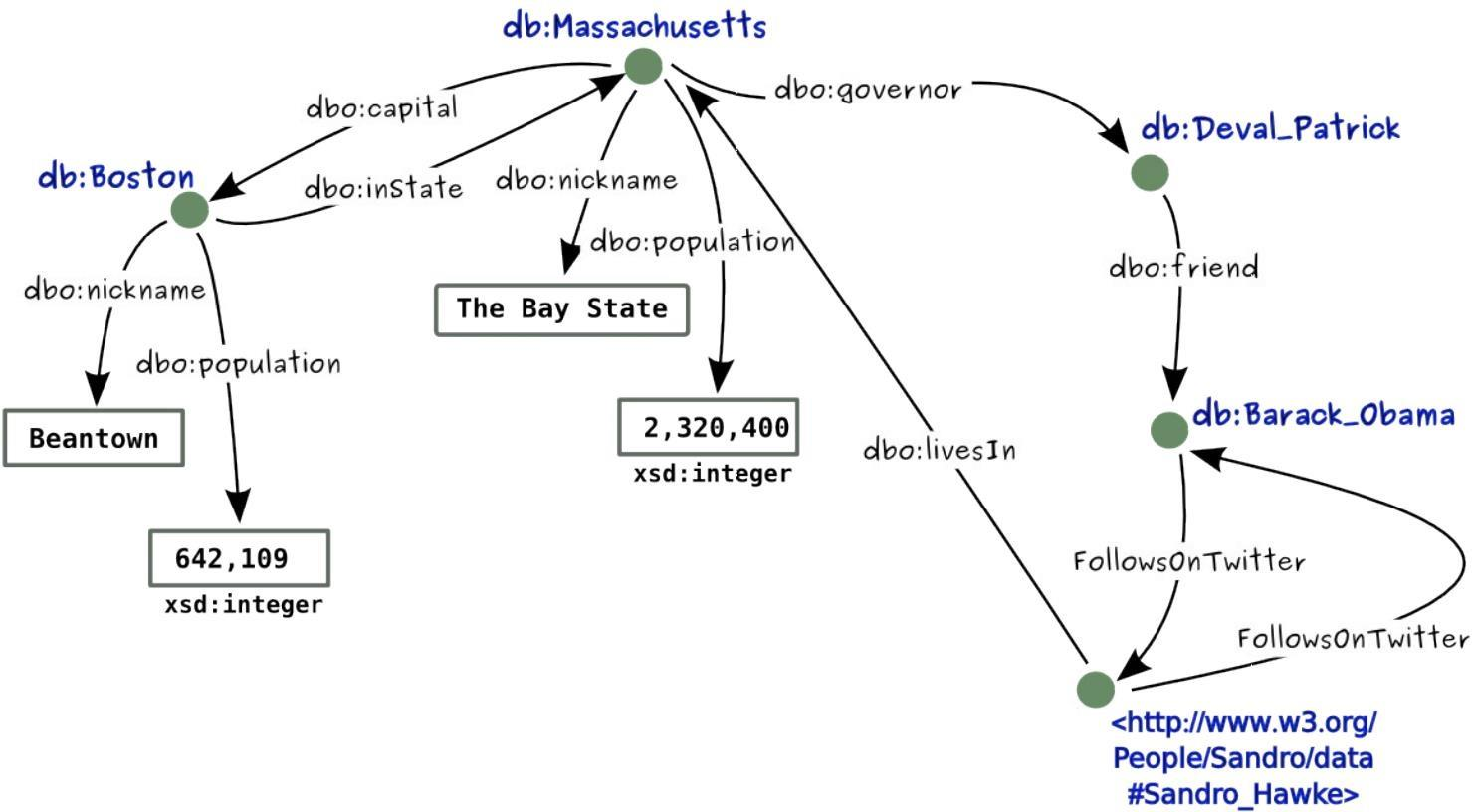
因此在上面的 “Boston” 和 “Nickname” 的问题我们有下面的解决方式:
- URI: http://dbpedia.rig/resource/Boston
- QName: db:Boston
- URI: http://example.org/terms/nickname
- QName: dbo:nickname
上面的RDF Graph 可以重新写成如下的形式:
2.2.2 RDF Triple
graph LR; A[subject] -->|predicate| B[object]
- subject: Resource or Blank node
- predicate: Resource
- Object: Resource, literal or Blank node
Resource are IRIs
- data value
- encoded as strings
- interpreted by datatypes
- treated the same as strings without datatypes, called plain literal;
- A plain literal may have a language tag
- Datatypes are not defined by RDF, but usually from XML Schema.
两种主要类型
- Typed Literals(带类型的字面量):
- “Beantown”^^xsd:string
- “The Bay State”^^xsd:string
- Plain literal and literals with language tags(普通字面量和带语言标签的字面量):
“France” “France”@en “France”@fr “法国”@zh “Frankreich”@de
字面量相等规则:
“001”^^xsd:integer = “1”^^xsd:integer
“123.0”^^xsd:decimal = “00123”^^xsd:integer (based on datatypes hierarchy)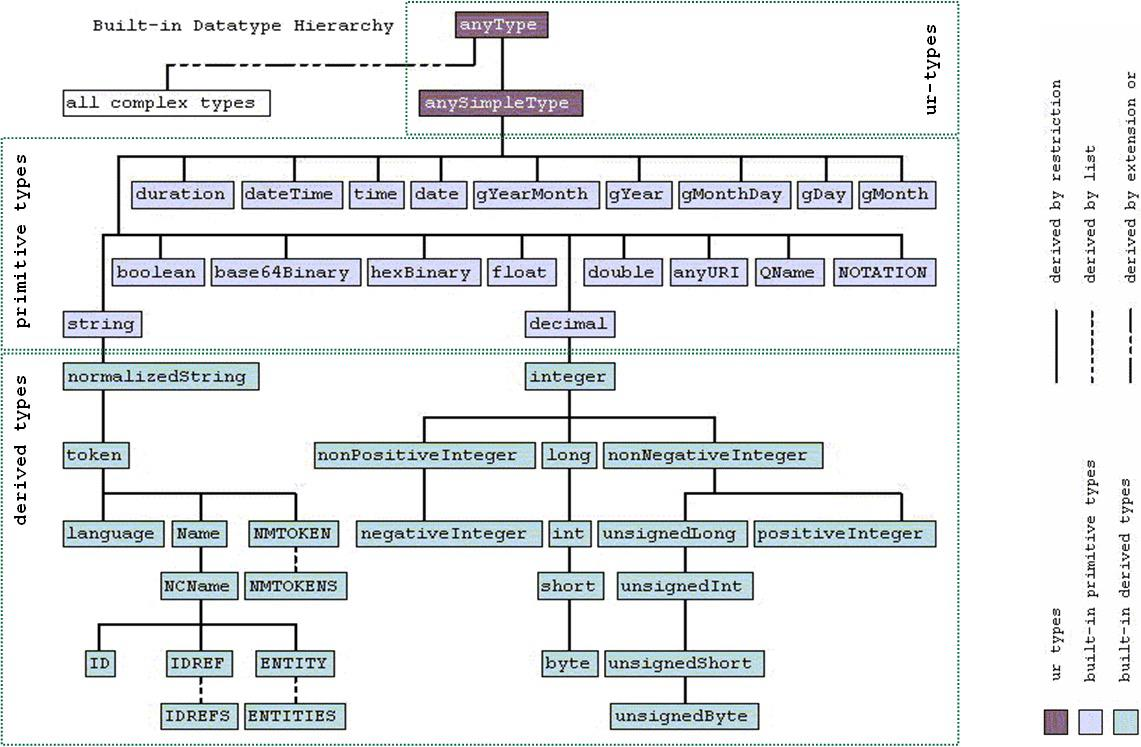
Blank ndoe: unnamed resource or complex node (later)
- blank node 、IRI、Literal 是互斥的,一个节点中只能是其中一个类型
- 空白节点通常用 _:作为前缀,后面添加一个本地ID,例如_:xyz,_:bn
- 空白节点的作用域:只在当前文件或数据图谱内部有效。
示例:
Guilin Qi is a speaker of a KG lecture.
graph LR; A[ex:Guilin Qi] -->|ex:Speaker| B[_:x]; B -->|ex:theme| C[ex:KG]
@prefix ex:<http://exmaple.org/>.
2.2.3 RDF Syntax
序列化格式:Turtle,N-Triples, N-Quads, JSON-LD,N3,RDF/XML,RDF/JSON
2.2.3.1 Turtle
Turtle(Terse RDF Triple Language):
- S P O 三元组格式
- IRIs 用尖括号表示<IRIs>
- 三元组以句号结尾
- 空白字符会被忽略
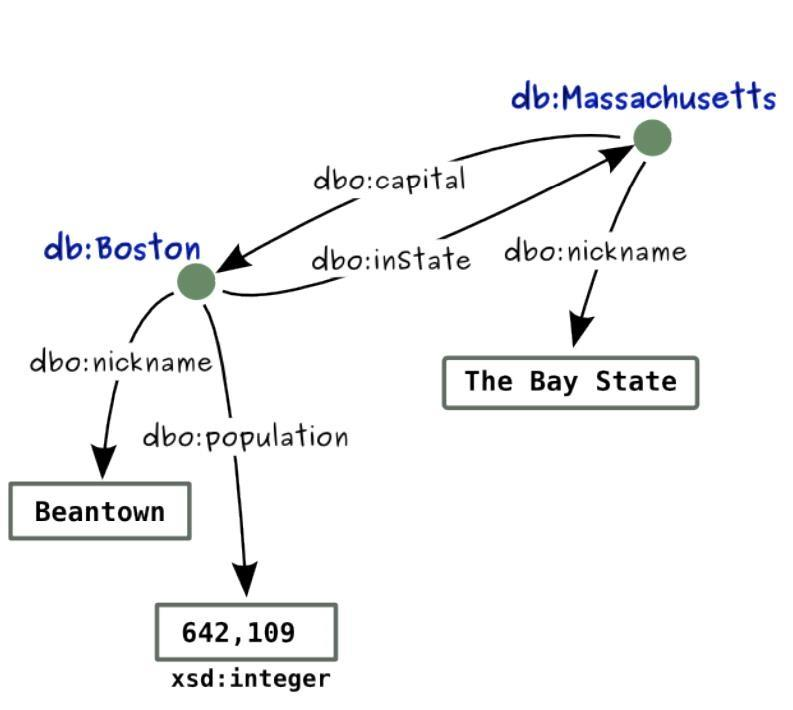
1 | <http://dbpedia.org/resource/Massachusets> <http://example.org/terms/captial> |
1 | @prefix db: <http://dbpedia.org/resource/> . |
- 使用分号;对具有相同主语的三元组进行分组;
- 使用逗号,对具有相同主语和谓语的三元组进行分组。
1 | @prefix db: <http://dbpedia.org/resource/> . |
2.2.3.2 RDF/XML
RDF最初是在XML的基础上发展而来的,如今很多工具和库都支持XML
命名空间用来区分标签的含义,属于RDF的标签有固定的命名空间,简称”rdf”


2.2.3.3 N-ary Relations
RDF是一个三元组模型,合适表示二元关系,但现实中存在着大量的多元关系,我们可以通过映入一个中间节点来完成这个任务。
示例:
所有的多元关系都可以二元化,这个过程成为具体化。我们在这个过程中通常使用 blank node来帮助构建二元关系。
RDFS

三元组能够有效的表达和使用,但是不能覆盖所有知识,尤其是复杂关系。
- RDFS 为RDF提供数据建模词汇
- 基础RDF词汇的扩展
- 为RDF数据提供了一致的解释
- 运行指定模式知识
- 是 W3C 推荐标准的一部分
2.3.1 Class and Instance
给定一个三元组:
ex:SemanticWeb rdf:type ex:Textbook
这个表达的是SemanticWeb是一本教科书,SemanticWeb 是Textbook的一个具体的实例。但是仅从URI/IRI的表达来看,我们无法知道ex:SemanticWeb 和 ex:Textbook哪一个是个体实例,哪一个是群体类。
RDFS提供了解决方案,他可以来声明某个资源是一个类。
ex:Textbook rdf:type rdfs:Class
2.3.2 Class hierarchy
类的层次结构具有传递性,例如:
如何在RDF/CML中定义一个类:
2.3.3 Property Restrictions
rdfs:domain:定义了Subject的类型
rdfs:range:定义类Object的类型
例如:
ex:isMarriedTo rdfs:domain ex:Person .
ex:isMarriedTo rdfs:rtange ex:Person .
2.3.4 Reification
利用blank node来描述一个多元的复制关系
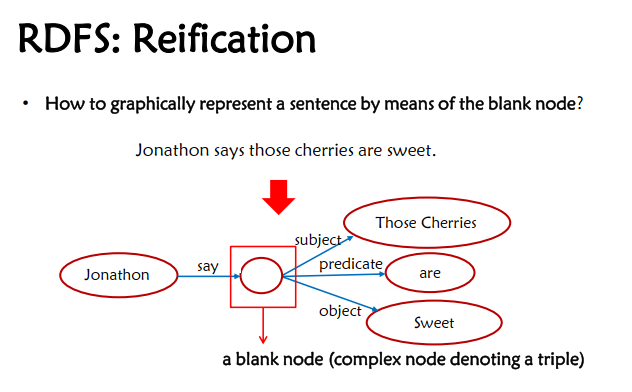
Exercise: Lee is a speaker of conference and its theme is Artifical Intelligence
Answer:
graph LR; A[Lee]-->|SpeakerOf| B[Blank node]; B -->|rdfs:type| C[conference]; B -->|theme| D[Artifical Intelligence]
Exercise

