自监督学习定义:
- 是无监督学习(Unsupervised Learning)的一种特例。
- 核心机制:学习器从数据本身“凭空制造”标签(Make up labels),然后解决一个监督任务。这个任务被称为前置任务(Pretext Task)。
- 目的:我们并不在乎前置任务做得好不好(比如拼图拼得对不对),在乎的是模型通过解决该任务学到的**特征表示(Representations)**是否有利于下游任务(如分类、检测)。
三种形式:
- 数据预测 (Data Prediction):基于部分数据预测另一部分。
- 变换预测 (Transformation Prediction):对数据做变换,让模型预测变换方式。
- 对比学习 (Contrastive Learning):最主流的方法,拉近相似数据,推开不相似数据
1 Data Prediction
1.1 Colorization
- 前置任务 (Pretext Task):
- 输入:灰度图像(即 Lab 颜色空间中的 L 通道,表示亮度)。
- 输出:彩色图像(预测 a、b 通道,表示颜色信息)。
- 核心直觉:
- 模型如果想给一张图片正确上色,它必须先识别出图片里“是什么”。比如,看到上面是平滑的灰色区域,它需要理解这是“天空”才能填蓝色;看到下面有纹理的区域,理解这是“草地”才能填绿色。
- Color + local cues:例如看到“云朵”纹理 -> 预测白色
- 具体实现 (Zhang et al. ECCV 2016):
- 并不直接回归预测具体的RGB数值(因为多模态分布会导致预测出灰褐色的平均值)。
- 而是将颜色空间量化为 313 个离散的类别(bins),将问题转化为一个分类问题,预测每个像素的颜色概率分布。
- 存在的问题 (Challenges):
- 固有歧义性 (Inherent Ambiguity):有些物体的颜色是不固定的。例如人造物体(车、衣服),灰度图里的一辆车可能是红色也可能是蓝色。模型在不知道确切答案时,可能会难以决策(课件中举了特朗普演讲的例子,领带颜色不论是红是蓝都看着很自然)。
- 偏差 (Biases):模型会学到统计学上的偏差。例如课件中展示的狗狗图片,模型只要看到狗的形状,哪怕狗闭着嘴,模型有时也会在嘴部位置染出一块粉色,因为它“认为”狗总是有舌头的。
- 扩展应用:
- 视频上色:利用视频的时间连贯性(Temporal Coherence)。如果这一帧物体是红色的,下一帧它大概率还是红色。这种约束可以让模型在学习上色的同时,学会无监督的目标追踪 (Tracking)。
1.2 图像修复/补全
- 前置任务:
- 在图像中随机挖掉一块方形区域(Mask)。
- 要求模型利用周围的像素(Context)来补全中间缺失的内容。
- 代表工作:Context Encoders (Pathak et al., 2016)。
- 学到了什么:
- 模型必须理解图像的局部纹理连贯性以及全局语义(比如看到窗户的左半边,就要补出窗户的右半边)。
- 损失函数的演进:
- $Loss = reconstruction + Adversarial Loss$
- 如果只用 L2 重建损失(Reconstruction Loss),补全的区域往往是模糊的(Blurry),因为模型倾向于预测所有可能性的平均值。
- 引入 对抗损失(Adversarial Loss,即 GAN 的思路):判别器(Discriminator)会判断补全的图片是否逼真,这迫使生成器生成纹理更清晰、细节更丰富的填补内容。
数据预测类方法是自监督学习的早期探索,其特点如下:
- 优点:不需要任何额外的人工标签,数据本身就是标签(Self-labeled)。
- 缺点:模型往往过于关注像素级别的细节(pixel-level details),这对于高层语义理解(如分类)来说可能过于琐碎,且计算量较大。
- 后续发展:这类方法后来被对比学习(Contrastive Learning)超越,但最近随着 MAE (Masked Autoencoder) 的提出,基于“完形填空”的数据预测思路又强势回归,成为了Vision Transformer时代的主流预训练范式。
2 Transformation Prediction
2.1 Context Prediction
- 出处:ICCV 2015 (Doersch et al.)
- 前置任务:
- 从图片中随机取一个中心图像块(Patch)。
- 再从它周围的8个邻域中随机取一个块。
- 让模型预测第二个块相对于第一个块的位置(是“右上”?“左下”?还是“正下”?)。
- 目标: 学习 空间关系和 全局语义
- 核心逻辑:
- 如果你只看到一个“车轮”和一个“车窗”,想要判断出“车轮在车窗的左下角”,你必须先在脑海里识别出**“这是一辆公交车”**这个宏观概念,并且知道公交车的结构长什么样。
- 因此,通过学习相对位置,模型被迫学到了全局语义 (Global Semantics) 和物体结构。
2.2 Jigsaw Puzzle Solving
- 出处:ECCV 2016 (Noroozi & Favaro)
- 前置任务:
- 将图片切成 3x3 的9个宫格。
- 打乱顺序(Shuffle)。
- 让模型预测这9个块的正确排列顺序(Reassemble)。
- 特点与细节:
- 更高效:作者声称这比上下文预测更简单,训练更快。
- 架构设计 (CFN):使用“上下文无关网络”(Context Free Network),即这9个块在进入全连接层之前,是分别独立通过卷积层的。这迫使模型专注于提取每个块的局部特征。
- Focus on local representations
2.3 Rotation Prediction
- 出处:ICLR 2018 (Gidaris et al.)
- 前置任务:
- 将一张图片旋转 0°、90°、180° 或 270°。
- 让模型做一个 4分类任务:这张图到底转了多少度?
- 核心直觉 (Core Intuition):
- 如果一个人不知道图片里画的是什么物体,他是无法判断图片是否“正”了的。
- 例如,只有当模型识别出图片里是“一只鸟”或者“一只青蛙”,并且理解它们的头应该朝上、脚应该朝下(Pose/Concept),它才能正确判断旋转角度。
- 这种方法迫使模型学习高层的语义概念 (High-level semantics)。
- 结果:
- 旋转预测在分类、检测和分割任务上的迁移效果,都优于上下文预测和拼图游戏,是这类方法中的佼佼者。
2.3.1 Task Gap
Example
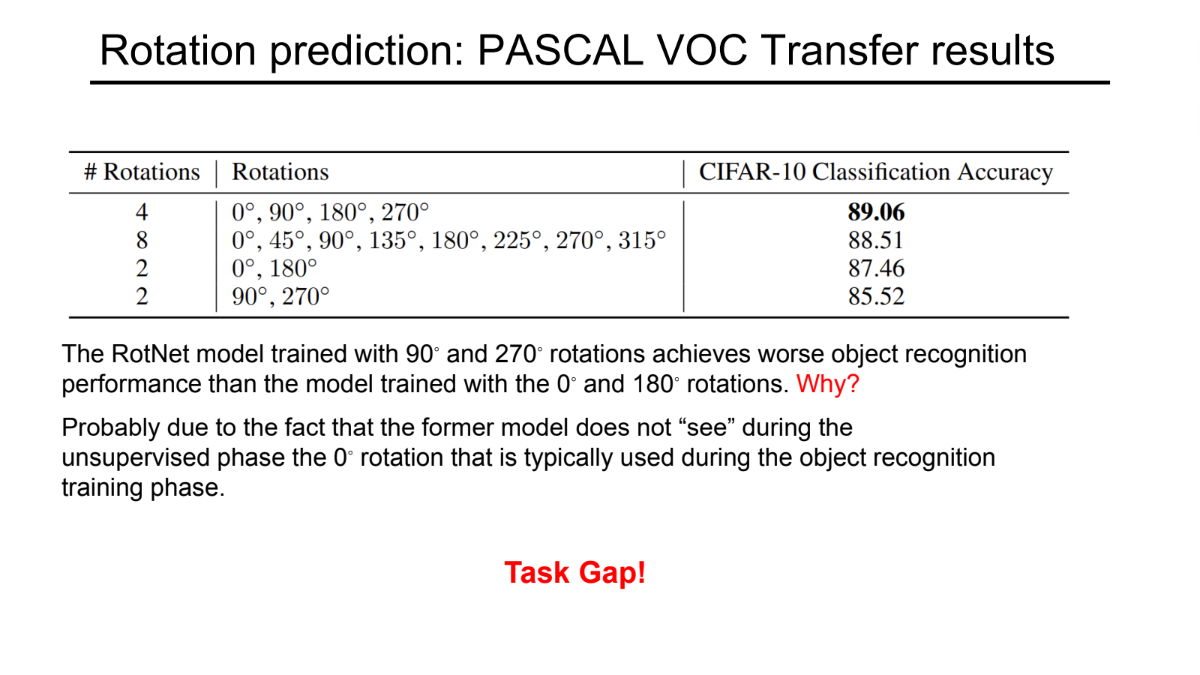
1. 实验背景:什么是旋转预测?
在自监督学习中,我们不给图片打标签,而是设计一个“前置任务”(Pretext Task)让模型自己去学。
这里的任务是:把一张图片旋转(比如转90度),然后让神经网络去猜这张图到底被转了多少度。通过猜角度,模型能被迫学会理解图片里的物体结构(比如“头通常在上面,脚通常在下面”)。
2. 表格数据分析
表格展示了使用不同的旋转角度组合进行预训练后,模型在CIFAR-10分类任务上的准确率表现:
- 最佳表现(4 Rotations): 使用 $0^\circ, 90^\circ, 180^\circ, 270^\circ$ 四个角度训练,准确率最高 (89.06%)。这意味着让模型看全四个方向,学到的特征最丰富。
- 过度旋转(8 Rotations): 增加到8个角度反而略有下降 (88.51%),可能是任务变难了,或者多余的角度带来的噪声多于信息。
- 关键对比(2 Rotations): 这是本页的重点。
- $0^\circ, 180^\circ$ 组: 准确率 87.46%。
- $90^\circ, 270^\circ$ 组: 准确率 85.52%(表现最差)。
3. 核心问题与解释(Task Gap)
幻灯片提出了一个问题:为什么只用 $90^\circ$ 和 $270^\circ$ 训练的模型,效果比用 $0^\circ$ 和 $180^\circ$ 训练的差?
原因(红字 “Why?” 下方的解释):
- 训练阶段: $90^\circ/270^\circ$ 的模型在无监督预训练时,从来没有见过 $0^\circ$(正向/直立) 的图片。它只见过横着的图片。
- 应用阶段: 在真正的物体识别(Object Recognition)任务中,大部分图片都是 $0^\circ$(正向) 的。
- 结果: 模型在预训练时没见过“正常视角”的物体,导致它提取的特征在处理正常图片时不够好。
4. 结论:Task Gap(任务差距)
底部红色的 “Task Gap!” 总结了这一现象:
预训练任务(Pretext Task)和下游任务(Downstream Task)之间的数据分布必须尽可能一致。
- 如果预训练时模型“看”到的世界(比如全是横着的图),和实际应用时“看”到的世界(全是正着的图)不一样,就会产生鸿沟(Gap),导致迁移学习的效果变差。
- 这就是为什么包含 $0^\circ$ 的组合通常表现更好的原因。
一句话总结:
要想模型效果好,自监督学习的“练习题”(预训练)必须和“期末考试”(实际任务)长得像,不能让模型在练习时从来没见过考试要考的内容(比如正向的图片)。
核心思想:
- 关注“视觉常识” (Visual Common Sense):
- 这些前置任务(Pretext tasks)的设计初衷,是考察模型是否具备人类那样的“常识”。
- 举例:如果模型不知道“鸟是长什么样子的”,它就没法把打乱的拼图拼回去,也没法判断这张图是不是被倒转了。
- 强迫学习语义特征 (Forced to learn good features):
- 为了完成这些任务,模型被迫去学习图像的高层语义信息(Semantic representation)。
- 它不能只靠死记硬背像素,必须理解物体的类别、形状和结构,才能解答出“旋转了多少度”或者“哪里缺了一块”。
- 醉翁之意不在酒 (Focus on downstream tasks):
- 这是非常关键的一点。我们其实并不在乎模型拼图拼得好不好,或者旋转角度猜得准不准(这些任务本身没有实际应用价值)。
- 我们在乎的是:通过训练这些任务,模型学到的特征提取能力,能不能迁移到下游任务(如图像分类、目标检测、语义分割)中去,帮助我们在标签很少的情况下也能训练出好模型。
存在问题:
- 设计任务很繁琐 (Coming up with individual pretext tasks is tedious):
- 你需要人工去构思各种巧妙的任务(是拼图好?还是旋转好?还是变色好?)。这种“手工设计”的过程效率很低,且很难穷尽。
- 学到的特征可能不通用 (Representations may not be general):
- 模型可能会为了解决特定的前置任务而“钻牛角尖”,学到一些只对该任务有用但对识别物体无用的特征(Trick features)。
- 比如,为了识别旋转,模型可能只关注边缘的线条方向,而忽略了物体的颜色或纹理。
- 前置任务与下游任务存在鸿沟 (Gap between pretext and downstream tasks):
- 这对应了前面 PPT 提到过的例子:如果你训练模型识别 90°/180°/270° 的旋转,但下游任务(如正常的物体识别)给的都是 0° 的正常图片。
- 模型在预训练阶段从未见过“正常角度”的图片,这导致预训练学到的知识在迁移到下游任务时会有损失。
3 Constrastive Learning
3.1 核心思想
- 正样本(Positive Pairs)- “拉近”:
- 对于同一张图片 $x$,通过数据增强(如裁剪、变色)生成两个不同的版本(视图)$x$ 和$x^+$。
- 模型应该认为这两个视图本质上是同一个东西,因此在特征空间中要把它们拉近(Attract)。
- 负样本(Negative Pairs)- “推开”:
- 对于其他不同的图片(比如 $x$ 是猫,$x^-$ 是狗),模型应该认为它们是不同的,因此要在特征空间中把它们推开(Repel)。
- 目标:学习一个特征空间,使得同类样本聚集,异类样本分散
3.2 InfoNCE Loss
InfoNCE Loss(Information Noise Contrastive Estimation Loss)是自监督学习和对比学习(Contrastive Learning)中最核心、最常用的损失函数。
InfoNCE Loss 的本质是一个 $K+1$ 类的分类问题。
想象你在做一个选择题:
- 题目(Query): 给你一张“猫”的照片。
- 选项(Keys): 只有 1 个选项是这只猫的另一张照片(正样本),其余 $K$ 个选项是狗、车、飞机等不相关的照片(负样本)。
- 目标: 模型需要从这 $K+1$ 个选项中,准确地把那个“正样本”选出来。
为了选对,模型必须学会提取图像的本质特征(比如猫的耳朵、胡须),而不是死记硬背像素。
数学公式
对于一个查询样本 $q$,它有一个正样本 $k_+$ 和 $K$ 个负样本 $k_-$。InfoNCE Loss 的公式如下:
$$
\mathcal{L}q = - \log \frac{\exp(\text{sim}(q, k+) / \tau)}{\sum_{i=0}^{K} \exp(\text{sim}(q, k_i) / \tau)}
$$
其中:
- $q$ (Query): 查询样本的特征向量(例如:经过编码器后的向量)。
- $k_+$ (Positive Key): 与 $q$ 属于同一来源的正样本向量(例如:同一张图的另一种增强)。
- $k_i$ (Keys): 所有的键向量,包含 1 个正样本和 $K$ 个负样本。
- $\text{sim}(\cdot, \cdot)$: 相似度度量,通常是余弦相似度(Cosine Similarity)。
- $\tau$ (Temperature): 温度系数(超参数),用于控制模型对负样本的区分力度。
公式本质: 这其实就是 Softmax + Cross Entropy(交叉熵损失)。分子是正样本的得分,分母是所有样本得分的总和。我们要最大化正样本的概率(即最小化 Loss)。
InfoNCE Loss 在优化过程中主要做两件事(也被称为 Alignment 和 Uniformity):
拉近正样本 (Alignment):
公式的分子部分希望 $\text{sim}(q, k_+)$ 越大越好。这意味着同一张图的不同视角,在特征空间里应该重合。
推远负样本 (Uniformity):
公式的分母部分包含所有负样本的相似度。为了让分式的值变大(Loss 变小),模型必须让分母尽可能小,也就是让 $q$ 和所有 $k_-$ 的相似度尽可能低。这防止了所有特征都聚在一起(Collapse),迫使特征均匀分布在特征空间(通常是超球面)上。
$\tau$ 是一个非常关键的超参数,通常设为 0.07 或 0.1 等较小的值。
- $\tau$ 越小:分布越尖锐。模型会非常关注那些特别困难的负样本(Hard Negatives),哪怕一点点相似度也会被放大,惩罚力度很大。这能让模型学到更细粒度的特征,但如果太小可能导致训练不稳定。
- $\tau$ 越大:分布越平滑。模型对所有负样本一视同仁,对困难负样本的关注度降低,学习到的特征可能比较泛化但不够锐利。
3.3 SimCLR
- 流程:输入图像 $\rightarrow$ 强数据增强 $\rightarrow$ 编码器 $\rightarrow$ 投影头 (Projection Head) $\rightarrow$ Contrastive Loss。
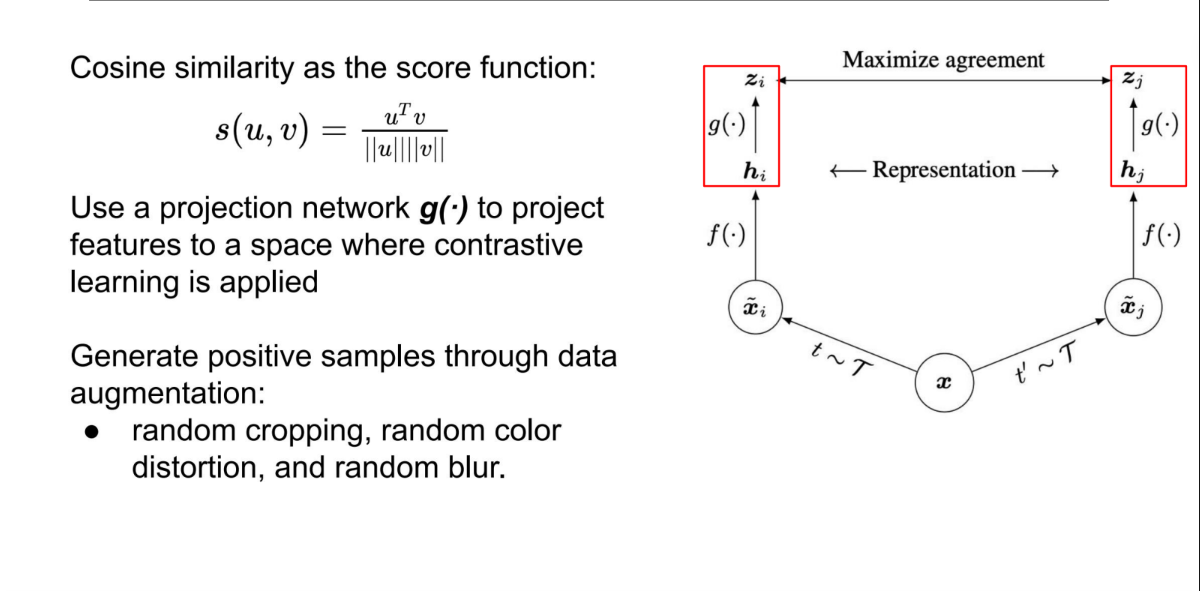
- 关键点:
- 数据增强至关重要:必须使用随机裁剪(Random Crop)配合颜色抖动(Color Distortion)。如果没有颜色抖动,模型可能会利用颜色直方图作弊,而不学习形状特征。
- 非线性投影头:在特征层之后加一个 MLP(投影头 $g(\cdot)$)再算 Loss,效果显著提升。
- 局限性:SimCLR 的负样本直接取自同一个 Batch 中的其他图片。为了保证有足够的负样本来“推开”,它需要巨大的 Batch Size(如 4096甚至8192),这对显存(TPU/GPU)要求极高。
3.4 MoCo
- 动机:解决 SimCLR 需要超大 Batch Size 的问题。
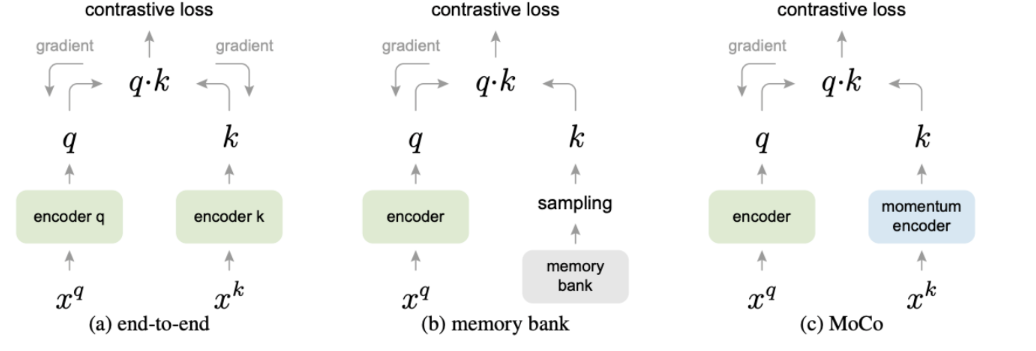
MoCo 通过两个核心设计,将“负样本数量”与“Batch Size”解耦(Decouple):
队列 (Queue / Dictionary):
- MoCo 维护一个先进先出(FIFO)的队列来存储负样本的特征。
- 每训练一个 Batch,新的特征入队,最老的特征出队。
- 好处:队列的大小可以设得很大(比如 65536),与当前训练的 Batch Size(比如 256)无关。这让普通显卡也能跑得动大规模对比学习。
动量编码器 (Momentum Encoder):
- 问题:队列里的特征来自于过去不同时刻的编码器。如果编码器更新得太快,队列里的“旧特征”和当前的“新特征”分布就不一致(Inconsistent),导致无法比较。
- 解决:
- 设置两个编码器:Query Encoder ($f_q$) 和 Key Encoder ($f_k$)。
- $f_q$ 使用正常的梯度下降更新。
- $f_k$ 不进行梯度回传,而是通过动量更新(Momentum Update):
$$ \theta_k = m \cdot \theta_k + (1-m) \cdot \theta_q $$
(其中 $m$ 是很大的动量系数,如 0.999)。
- 效果:Key Encoder 更新得极其缓慢和平滑,保证了队列里的特征在一段时间内是相对**一致(Consistent)**的,让对比学习更稳定。
3.5 MoCo v2
在 MoCo 发布后不久,Google 提出了 SimCLR。虽然 SimCLR 极其吃算力,但它证明了两件事对提升效果至关重要:
- 非线性投影头 (Non-linear Projection Head):在编码器后面加一个两层的 MLP(全连接层+ReLU),而不是直接用编码器的输出算 Loss。
- 更强的数据增强 (Strong Data Augmentation):特别是模糊(Gaussian Blur)和更强的颜色抖动。
核心改进:
MoCo v2 = MoCo 的架构 + SimCLR 的技巧
MoCo v2 本质上是一个“集大成者”,它吸取了 SimCLR 的优点并应用在 MoCo 的框架上:
- 保留 MoCo 的优点:继续使用动量编码器和队列,不需要大 Batch Size(普通 GPU 友好)。
- 引入 SimCLR 的优点:
- 加入了 MLP Projection Head。
- 加入了 数据增强(模糊 + 颜色增强)。
| 模型 | MLP Head | 数据增强+ | Batch Size | ImageNet 准确率 |
|---|---|---|---|---|
| MoCo v1 | No | No | 256 | 60.6% |
| SimCLR | Yes | Yes | 256 | 61.9% (Batch太小效果差) |
| SimCLR | Yes | Yes | 8192 | 66.6% (这就需要大算力了) |
| MoCo v2 | Yes | Yes | 256 | 67.5% |
为什么对比学习有效
- L2 归一化 (Normalization):
- 在计算相似度之前,特征向量都会做 L2 归一化,投射到一个超球面上。
- 这意味着模型不关注特征向量的长度(Magnitude),只关注方向(Angle)。这对应了余弦相似度。
- 分布特性:
- 损失函数迫使正样本在球面上靠得很近(Alignment),同时迫使所有样本在球面上均匀分布(Uniformity),最大限度地利用特征空间。
扩展应用
- 将对比学习应用到图像-文本对上(Image-Text pairs),学习到了极强的零样本分类能力。
- DenseCL:解决了全局对比学习(分类任务)与密集预测任务(检测、分割)之间的 Task Gap。在像素级别进行对比学习。
4 Deep Clustering
- 对比学习的问题:在 SimCLR 或 MoCo 中,我们将每一张图片都视为一个独立的类别(Instance Discrimination)。
- 这意味着,如果有两张不同的图片都是“狗”,对比学习会把它们视为负样本(Negative Pairs),在特征空间中强制把它们推开。
- 但从语义上讲,这两只狗应该聚在一起。
- 解决方案:不再把每张图当成唯一的类,而是利用聚类(Clustering)算法,将相似的图片归为一组,自动生成“伪标签”(Pseudo-labels),然后让网络去学习分类。这样既不需要负样本,又能学到语义类别。
4.1 Deep Cluster
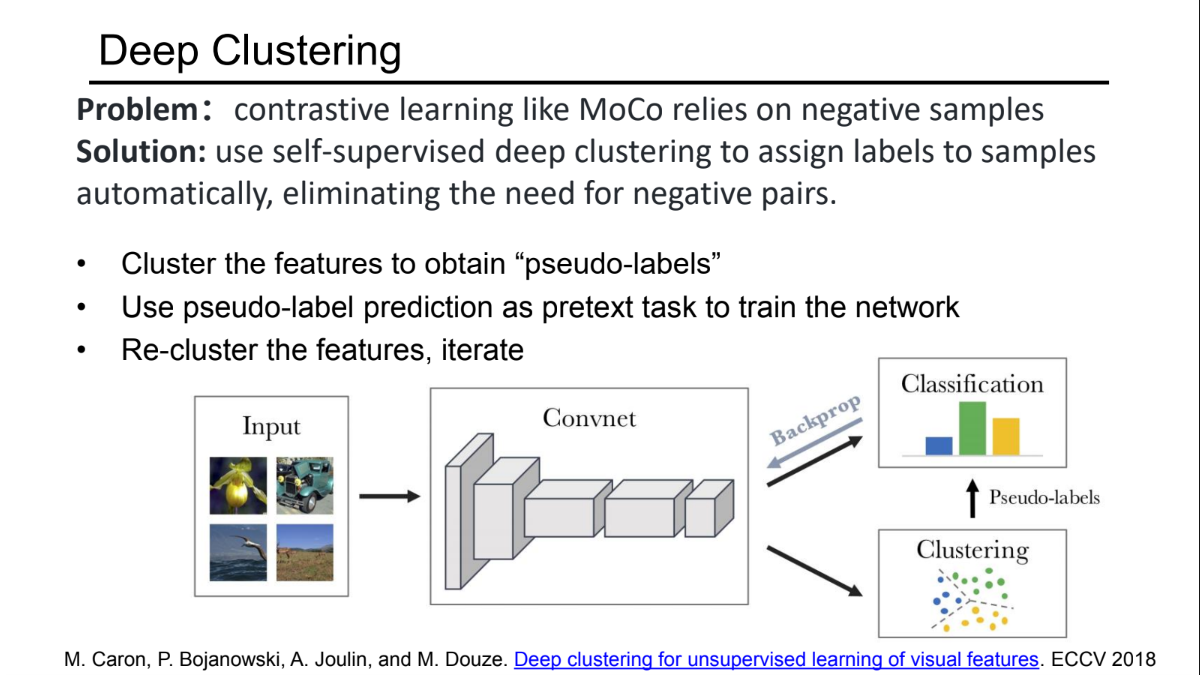
- 工作流程:
这是一个迭代(Iterative)的过程:- 特征提取:用当前的卷积神经网络(ConvNet)提取所有图像的特征。
- 聚类 (Clustering):对这些特征运行聚类算法(通常是 K-Means),将数据分成 $k$个簇。
- 伪标签生成 (Pseudo-labeling):每个图片所属的簇 ID(比如 Cluster #5)就变成了它的“标签”。
- 监督训练 (Prediction):把这个无监督任务变成一个有监督的分类任务。训练 ConvNet 去预测每张图片的簇 ID。
- 循环:网络更新后,特征会变,所以需要重新提取特征、重新聚类、重新训练。
- 优点:不需要定义复杂的正负样本对,直接利用了卷积网络提取共性特征的能力。
4.2 SWaV
- 地位:它是 DeepCluster 的进化版,彻底解决了 DeepCluster 需要“离线聚类”(必须等所有图片算完特征才能聚类,速度慢)的问题。
- 核心思想:
- 它不需要负样本(对比学习痛点),也不需要离线的大规模聚类(DeepCluster 痛点)。
- “Swapping” (交换预测):
- 给定一张图片的两个增强视图(View A 和 View B)。
- 不直接比对特征距离,而是将 View A 的特征映射到一组“原型向量(Prototypes/Clusters)”上,得到一个聚类分配(Assignment/Code)。
- 让 View B 的特征去预测 View A 的那个聚类分配。反之亦然。
- 结果:SWaV 可以在小 Batch Size 下训练,且不需要像 MoCo 那样维护巨大的队列,同时也学到了非常好的语义特征。
5 Masked autoencoder
Masked Autoencoder (MAE) 是自监督学习领域(尤其是 Vision Transformer 时代)的最新前沿方法。
它标志着自监督学习的一个**“轮回”:从复杂的对比学习(Contrastive Learning)又回到了最直观的数据预测(Data Prediction)**思路,但做法上有了质的飞跃。
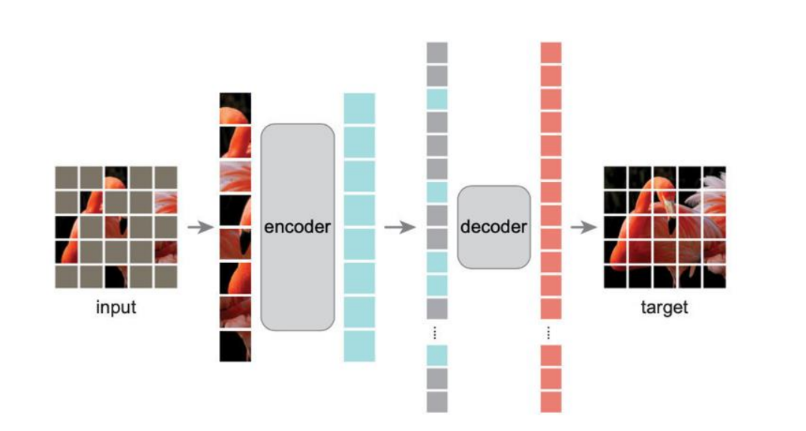
MAE 的工作流程非常简洁,分为四个步骤:
- 分块与掩码 (Patching & Masking):
- 将输入图像切分成一个个小的图块(Patches)。
- 关键点:随机掩盖掉极高比例的图块(例如 75%)。这与 BERT 在 NLP 中只掩盖 15% 的单词不同,视觉信息冗余度高,所以必须遮得够多,才能迫使模型去“猜”剩下的内容,而不是简单地通过邻居插值。
- 编码器 (Encoder):
- 只处理可见的图块 (Visible Patches)。
- 被遮住的那些块(Masked patches)根本不进入编码器。
- 这大大减少了计算量,因为编码器只需要处理 25% 的数据。
- 解码器 (Decoder):
- 输入是两部分:编码器输出的特征 + Mask Tokens(表示“这里缺了一块”的可学习向量)。
- 解码器的任务是还原原始图像的像素。
- 预测目标:
- 计算重建图像与原始图像在被掩盖区域的像素误差(MSE Loss)。
- 预训练结束后,解码器被丢弃,只保留编码器用于下游任务(如分类、检测)。
A. Asymmetric Design
这是 MAE 最精髓的地方:
- Encoder:很重(计算量大),但只看部分数据。
- Decoder:很轻(计算量小),但看所有位置的数据。
- 为什么要这样? 因为我们希望 Encoder 学到最强的特征提取能力,而 Decoder 只需要负责把像素画出来就行。这种非对称设计提高了训练效率。
B. 解决”捷径学习”问题
- 旧方法的弊端:早期的自动编码器(Autoencoder)或修复网络(Inpainting),编码和解码往往混在一起。如果让 Encoder 看到 Mask 标记,或者 Decoder 太强,模型可能会学到一些**“捷径”(Shortcuts)**——即仅仅根据 Mask 的位置边缘去猜像素,而不是真正理解图片内容。这会导致学到的特征对下游任务(如分类)没用。
- MAE 的解决:
- Encoder 完全看不见 Mask token。它只能看到实实在在的物体碎片。
- 这迫使 Encoder 必须根据仅有的碎片,通过全局上下文(Global Contexts)和局部连接(Local Connections),在脑海中重构出完整的物体语义,才能把特征传给 Decoder 去复原。
Local Connections + global contexts
- 局部连接:理解纹理、边缘是如何延续的。
- 全局上下文:这是最重要的。因为遮挡了 75%,模型如果只看局部是猜不出来的。例如,只看到一只狗的尾巴尖和半只耳朵,模型必须推理出“这是一只狗”,并根据狗的解剖结构推测出身体在哪里。这种推理能力正是我们想要的高层语义特征。
6 Other
Video, Audio, Language and Future Predict