1. 学习策略
四种基本策略:
- 监督学习 (Supervised)
- 无监督学习 (Unsupervised)
- 半监督学习 (Semi-supervised)
- 弱监督学习 (Weakly-supervised)
半监督学习 (Semi-supervised Learning)
半监督学习是弱监督学习的一种特殊情况(即“不完全监督”)。
**动机 (Motivation) **
- 在实际应用中,未标记的数据 (Unlabeled data) 很容易获取(例如网上的海量图片)。
- 已标记的数据 (Labeled data) 获取难度大、成本高(需要人工逐一标注)。
- 目标: 混合使用少量的标记数据和大量的未标记数据,以训练出比仅用标记数据更好的模型。
**直观原理 (Intuition) **
- 标记数据的作用是决定一个初始的分类边界 (Boundary)。
- 未标记数据的作用是帮助寻找更好的边界,即对边界进行细化 (Refinement)。
核心问题与解决方案
- 关键问题: 如何利用未标记数据来找到更好的边界?
- 解决方案:伪标签 (Pseudo-Labelling)
- 具体流程:
- 训练 (Train): 先利用手中的标记数据训练一个初始模型。
- 预测 (Predict): 使用该模型对未标记数据进行预测,生成预测标签(即伪标签)。
- 重训练 (Retrain): 挑选出预测置信度高(Confident)的伪标签数据,将其加入到训练集中,与原有的标记数据一起重新训练模型。
- 循环过程: 更好的边界 $\rightarrow$ 更可信的伪标签 $\rightarrow$ 更好的边界…
弱监督学习 (Weakly-supervised Learning)
弱监督学习是一个更广泛的概念,它不仅包含半监督学习,还包含其他利用“低质量”标签进行学习的场景。
**三种主要类型 (Types) **
- 不完全监督 (Incomplete Supervision):
- 即只有部分数据有标签,其余无标签。这也就是上述的半监督学习。
- 例子: 一堆西瓜图中,只有几个标了“西瓜”,其他的没标。
- 不确切监督 (Inexact Supervision):
- 给出的标签不够精确,粒度较粗。常用于多示例学习 (Multi-instance learning)。
- 例子: 任务是检测图片中的西瓜位置(Bounding box),但给的标签只是整张图是“西瓜”(Image-level label)。
- 不准确监督 (Incorrect/Inaccurate Supervision):
- 标签中包含错误,即标签噪声学习 (Label noise learning)。
- 例子: 图片明明是菠萝,标签却写着“西瓜”。
- 不完全监督 (Incomplete Supervision):
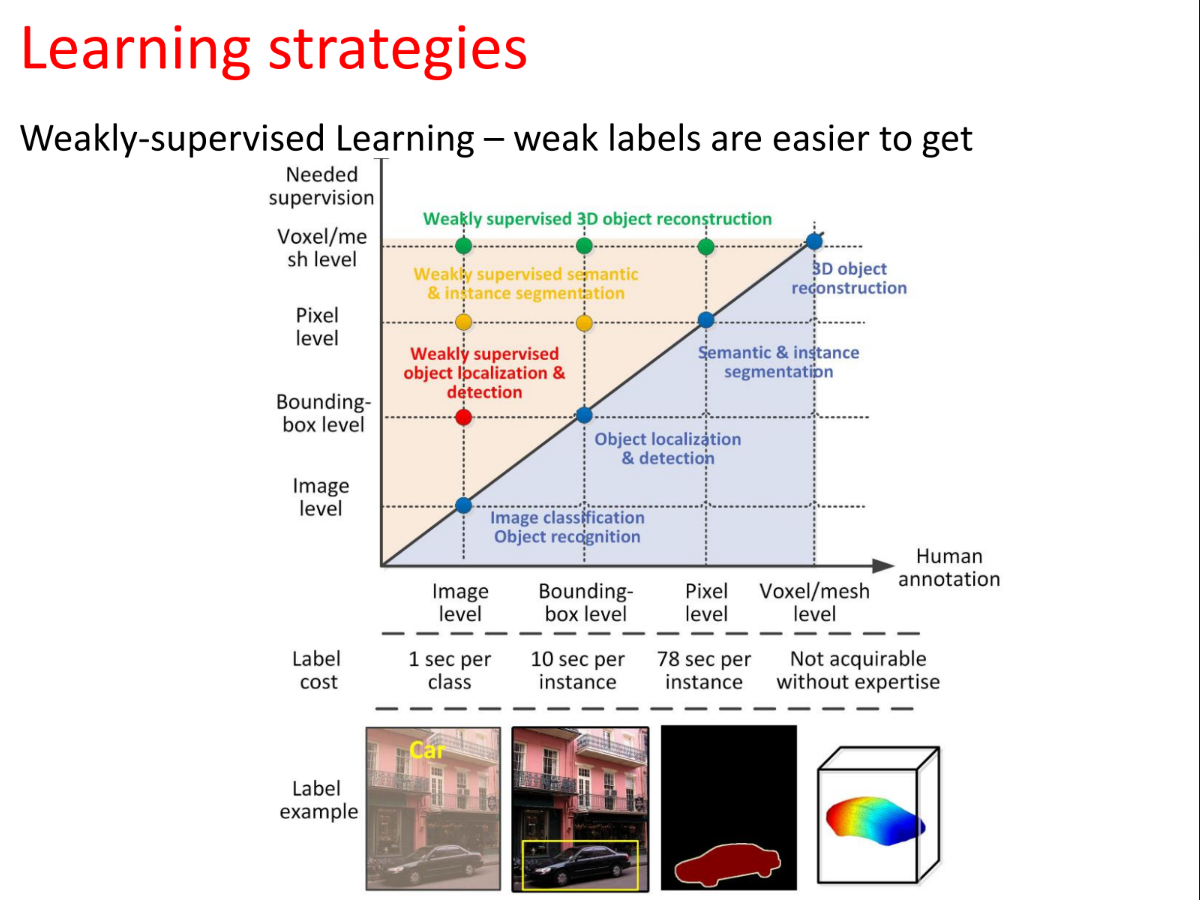
**为什么需要弱监督?(成本视角) **
- 强监督 (Strong Supervision): 如像素级分割(Pixel level)或体素级重建(Voxel level),标注极其耗时(每个实例需78秒甚至无法由非专家完成)。
- 弱监督 (Weak Supervision): 如图像级标签(Image level),只需告诉机器图里“有什么”,标注非常快(每个类仅需1秒)。
- 结论: 弱标签更容易获取,成本极低。
核心问题与解决方案
- 关键问题: 如何将粗粒度的标签(如图像级标签)“传播”或转化为细粒度的标签(如物体级/像素级标签)?
- 解决方案:两阶段学习框架 (Two-stage learning frameworks)
- 初始化 (Initialization): 利用先验知识 (Prior knowledge)。例如利用区域显著性 (Region Saliency)、物体性 (Objectness) 等,从粗标签中猜测潜在的物体位置。
- 细化 (Refinement): 训练物体模型并重新定位 (Re-locate)。
- 例子: 从“图像级标签” $\rightarrow$ 生成“注意力图 (Attention Map)” $\rightarrow$ 最终得到“物体级标签”。
特性 半监督学习 (Semi-supervised) 弱监督学习 (Weakly-supervised) 包含关系 是弱监督学习的一个子集 包含半监督、多示例学习、噪声标签学习 数据特点 少量有标签 + 大量无标签 标签不全、标签太粗(不确切)、或标签有错 主要策略 伪标签 (Pseudo-Labelling):用模型自产自销,逐步优化边界。 两阶段框架:利用先验知识将粗标签转化为细标签。 解决痛点 没钱/没时间给所有数据打标签。 没钱/没时间做精细的标注(如画框、抠图)。
2. 迁移学习
- 定义:迁移学习是指将一个模型在一个任务(源域)中学到的知识,应用到解决另一个不同但相关的问题(目标域)中。
- 对比传统机器学习:
- 传统机器学习:孤立地学习。对于每个新任务,都需要从头开始收集数据、训练系统。
- 迁移学习:知识的复用。模型可以利用已有的知识储备来帮助学习新任务,就像人类学会了骑自行车有助于学习骑摩托车一样。
2.1 General to Specific
神经网络的可迁移性原理
迁移学习之所以在深度学习中有效,是因为神经网络的层级结构具有“从通用到特定”的特性:
- 底层/浅层(Bottom Layers):是通用学习者(General Learners)。它们提取的是非常基础的视觉特征,如边缘、颜色、纹理和基本形状。这些特征在大部分图像任务中都是通用的。
- 高层/深层(Top Layers):是特定学习者(Specific Learners)。它们提取的是高度抽象的语义特征(如眼睛、羽毛、车轮等),这些特征与具体的训练数据集和任务紧密相关。
- 结论:在迁移时,我们通常保留底层参数(复用通用知识),而重新训练高层参数(适应新任务)。
2.2 迁移学习流程
- 获取预训练模型:通常是在大规模数据集(如ImageNet)上训练好的网络。
- 网络拆分:
- 特征提取器(Featurizers):确定哪些层需要保留并冻结(Frozen)。
- 分类器(Classifiers):确定哪些层(通常是全连接层)需要移除并替换。
- 重训练:用目标域的新数据训练新的分类层。
- 微调(Fine-tuning):解冻部分或全部网络权重,使用较小的学习率对整个网络进行微调。
2.3 何时以及如何微调?
这是迁移学习中最具实战指导意义的部分。策略的选择取决于目标数据集的大小以及与源数据集的相似度:
- 数据量大 + 领域差异大:
- 策略:从头训练模型,但可以使用预训练模型的权重作为初始化参数。
- 数据量大 + 领域相似:
- 策略:微调整个网络。因为数据量足够大,不易过拟合,微调可以让模型更好地适应细节。
- 数据量小 + 领域差异大:
- 策略:只训练分类器,且建议使用网络**较早层(Earlier layers)**的特征。
- 原因:因为高层特征太具体,不适合新领域;而数据太少,微调整个网络会导致过拟合。
- 数据量小 + 领域相似:
- 策略:不要微调网络,只在顶层训练一个线性分类器。
- 原因:数据太少容易过拟合,利用预训练好的高层特征直接分类效果最好。
3. 领域自适应
这是迁移学习中的一个特殊且重要的子任务。
- 任务描述:
- 源域(有标签)和目标域(无标签)的任务相同(如都是数字识别),但数据分布不同(Domain Shift,如MNIST手写体 vs MNIST-M彩色背景)。
- 目标: 消除域偏移 (Remove Domain Shift),桥接域差距。
- 三大类方法:
- 基于差异的方法 (Discrepancy-based): 在特征空间中设计距离度量(如MMD),最小化源域和目标域特征分布的距离。
- 基于对抗的方法 (Adversarial-based):
- 域对抗训练 (Domain-adversarial training): 引入梯度反转层 (Gradient Reversal Layer)。特征提取器试图“欺骗”域判别器(让其分不清数据来自源域还是目标域),同时特征还要能准确分类主任务标签。
- 基于GAN的方法: 生成对抗网络思路,使源域和目标域的编码对齐。
- 基于重构的方法 (Reconstruction-based): 利用数据重构作为辅助任务,迫使网络学习两个域共享的、具有不变性的特征表示。
4. 知识蒸馏
另一种形式的“知识迁移”,通常用于模型压缩。
- 核心思想: 将一个大型、复杂网络(Teacher)的知识“提炼”并传授给一个小型网络(Student)。
- 蒸馏的三种层次:
- 基于响应 (Response-based): 学习Teacher输出层的Logits(软标签),模仿最终预测分布。
- 基于特征 (Feature-based): 学习中间层的特征图或注意力图(Attention maps),不仅学结果,还学过程。
- 基于关系 (Relation-based): 学习样本之间或层之间的关系结构。
- 扩展: 跨模态蒸馏(Cross-modal distillation),例如利用Teacher的RGB数据训练只能看到Depth数据的Student。