1 Attention
1.1 Self-Attention
- 例子:句子 “I saw a saw” 中有两个 “saw”,前一个是动词“看见”,后一个是名词“锯子”。
- 痛点:要区分这两个词的含义,必须结合全局上下文(Global Context)。
- 传统方法的局限:
- FC (全连接层):视野固定,无法动态适应不同长度的输入。
- RNN:虽然能处理序列,但是串行计算(Non-parallel),长距离依赖难以捕捉(Memory 遗忘问题)。
- CNN:感受野(Receptive Field)固定,只关注局部。
Self-Attention 的目标:让模型在处理序列中的每一个元素时,都能“看”到序列中的所有其他元素,并根据相关性动态地决定关注哪些部分。
Q, K, V:
A. 三个关键角色
- Query ($q$):查询向量。代表“我想要找什么?”(Criterion)。
- Key ($k$):键向量。代表“我有什么特征?”(Public information),用于被 Query 进行匹配。
- Value ($v$):值向量。代表“我的实际内容是什么?”(Real information)。
B. 计算步骤
生成 Q, K, V:
输入向量 $a^i$ 分别乘以三个可学习的权重矩阵 $W^q, W^k, W^v$,得到 $q^i, k^i, v^i$。计算相关性 (Attention Score)(第8页):
拿当前的 $q^1$ 去和序列中所有的 $k$(包括它自己)做点积(Dot Product)。- 公式:$\alpha_{1,i} = q^1 \cdot k^i$
- 含义:计算两个向量的相似度。得分越高,表示两者越相关。
归一化 (Softmax):
将相关性分数 $\alpha$ 输入 Softmax 层,得到概率分布 $\alpha’$。- 作用:让所有分数的和为 1,强化高分,抑制低分。
加权求和 (Weighted Sum):
用归一化后的权重 $\alpha’$ 对所有的 Value ($v$) 进行加权求和,得到最终输出 $b^1$。- 公式:$b^1 = \sum_i \alpha’_{1,i} v^i$
- 结果:输出向量 $b^1$ 不再只是原来 $a^1$ 的信息,而是包含了整个序列中与它相关的信息(Global Context)。
矩阵化并行计算:
实际上,上述过程不是一个一个向量算的,而是打包成矩阵一次性计算:- $A = K^T Q$ (计算所有相关性分数)
- $A’ = softmax(A)$
- $O = V A’$ (直接得到输出矩阵)
1.2 Multi-Head Self-Attention
为什么只用一组 Q、K、V 不够?
- 原因:相关性有多种类型。例如在处理图像或文本时,有的关注“颜色”,有的关注“形状”;有的关注“语法结构”,有的关注“指代关系”。
- 机制:
- 初始化多组不同的 $W^q, W^k, W^v$ 权重矩阵。
- 每一组(Head)独立计算一套 Attention,捕捉不同的特征依赖(Slide 19 图示非常直观,不同的 Head 连线不同)。
- 最后将所有 Head 的输出拼接(Concat)起来,通过一个线性层融合。
- 目的:增强模型的表达能力(Enhance the representative ability)。
1.3 Self-Attention 与其他模型的对比
vs CNN:
- CNN:可以看作是简化版的 Self-Attention。因为它只关注邻域(感受野固定),且权重是固定的(Filter参数)。
- Self-Attention:是复杂版的 CNN。它的感受野是全局的,且权重是根据数据动态计算的(Learnable receptive field)。
- 结论:数据量少时,CNN 因其归纳偏置(Inductive Bias)效果好;数据量极大时,Self-Attention 这种灵活的结构效果更好(第28页图表)。
vs RNN:
- RNN:串行结构,难以并行化(Non-parallel),前面的输入要经过很多步才能传到后面,容易丢失信息。
- Self-Attention:高度并行(Parallel),任何两个位置的距离都是 1,极易捕捉长距离依赖。
2 Transformer
在 Transformer(2017年 Google《Attention Is All You Need》)出现之前,序列处理(如翻译、文本生成)主要由 RNN(循环神经网络)和 LSTM(长短期记忆网络)统治。它们有两个致命缺陷:
- 无法并行计算(慢): RNN 必须读完第一个词,处理完状态,才能读第二个词。这像是一个只能逐字阅读的学生,无法利用 GPU 的并行能力。
- 长距离依赖遗忘(忘): 当句子很长时,RNN 读到句尾往往已经忘了句首的信息(尽管 LSTM 缓解了这个问题,但仍不完美)。
Transformer 的革命性思路: 抛弃循环(Recurrence),完全依赖注意力机制(Attention)。它像是一个能够一眼看完全文(并行)并且能够瞬间关联文中任意两个词(全局关联)的超级阅读者。
2.1 Architecture
Transformer 是一个典型的 Encoder-Decoder(编码器-解码器) 结构。
- Encoder(左边部分 - “阅读者”):
- 任务:负责理解输入(比如将一句中文理解成抽象的语义向量)。
- 特点:它是双向的,能同时看到上下文。
- Decoder(右边部分 - “创作者”):
- 任务:负责生成输出(比如根据 Encoder 的理解,一个词一个词地写出英文翻译)。
- 特点:它是自回归的(Auto-regressive),写当前词时只能看已写出的词,不能看未来。
2.2 核心组件
Transformer 由多个堆叠的层(Layer)组成,每一层内部包含以下关键零件:
A. 输入阶段 (Input Stage)
由于 Transformer 没有循环结构,它天生不知道“我爱你”和“你爱我”中“你”的位置区别。
- Token Embedding:将单词转化为向量。
- Positional Encoding (位置编码):这是 Transformer 的补丁。它给每个词的向量加上一个位置标记(通过正弦/余弦函数或可学习参数),告诉模型“我是第一个词”、“我是第二个词”。
B. 自注意力机制 (Self-Attention) —— 灵魂
- 作用:让每个词都能关注到句子中其他所有词,并根据相关性聚合信息。
- Multi-Head (多头):像是给模型配了多副眼镜,一副看语法,一副看指代,一副看语义,最后把看到的信息拼起来。
C. 残差连接与层归一化 (Add & Norm) —— 骨架
- Residual Connection (残差连接):$Output = Input + Function(Input)$。这让原本的信息可以无损通过,防止网络过深导致梯度消失(ResNet 的思想)。
- Layer Normalization (层归一化):对每一层的数据进行标准化,让数据分布更稳定,加速训练收敛。
D. 前馈神经网络 (Position-wise FFN) —— 大脑
- Attention 负责“收集信息”,FFN 负责“处理信息”。
- 它是一个两层的全连接网络,对每个位置的向量独立进行非线性变换,增强模型的表达能力。
E. 掩码 (Masking) —— 规则
- Padding Mask:处理长短不一的句子,把补齐的 0 遮住,不让模型关注。
- Look-ahead Mask (用于 Decoder):在训练时,防止模型“作弊”看到还没生成的单词。
2.3 Transformer 变体及改进
现在的模型大多不再使用完整的 Encoder-Decoder 架构,而是根据任务需求分化为三大流派:
| 流派 | 代表模型 | 架构部分 | 核心特性 | 擅长任务 |
|---|---|---|---|---|
| Encoder-only | BERT, RoBERTa | 仅编码器 | 双向可见。能同时看到上下文,理解能力极强。 | 文本分类、情感分析、实体识别(理解类任务) |
| Decoder-only | GPT 系列, LLaMA | 仅解码器 | 单向可见(从左到右)。只能看到上文,预测下一个词。 | 文本生成、对话、代码补全(生成类任务) |
| Encoder-Decoder | T5, BART | 完整架构 | 结合了理解与生成能力。 | 机器翻译、文本摘要 |

2.3.1 降低计算复杂度
如何降低Attention的计算复杂度?
解决方案:不需要让每一个 Token 都关注序列中的所有其他 Token(全连接)。只需要关注“重要”的 Token,将注意力矩阵变得“稀疏”(大部分位置为0,不进行计算),从而将复杂度降低到近似 O(N)(线性级)
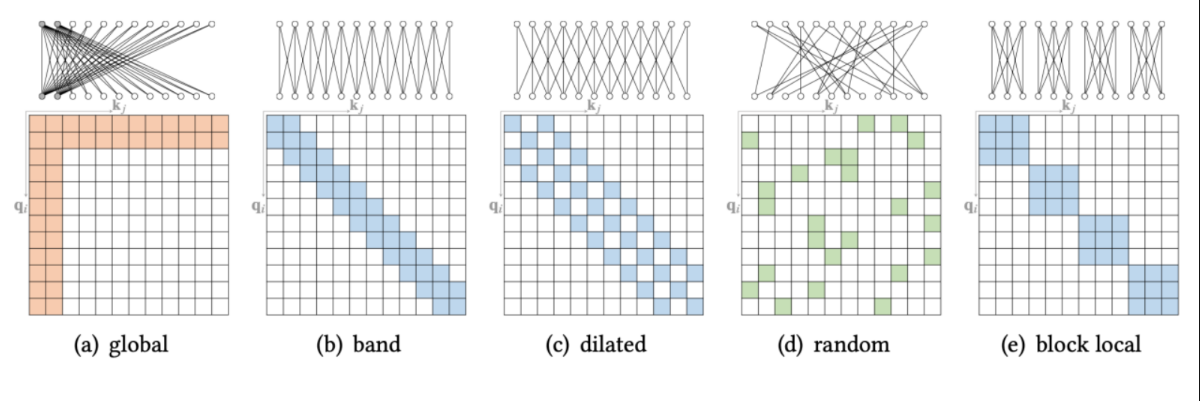
- Global(全局):特定的 Token(如 BERT 的 [CLS])关注所有其他 Token,或者所有 Token 都关注这几个特定的 Token。
- Band / Sliding Window(带状/滑动窗口):每个 Token 只关注它左右相邻的 看、 个 Token(类似 CNN 的卷积核)。
- Dilated(空洞):像空洞卷积一样,隔几个跳着关注,以扩大感受野。
- Random(随机):随机选择一些 Token 进行关注,
代表性模型:
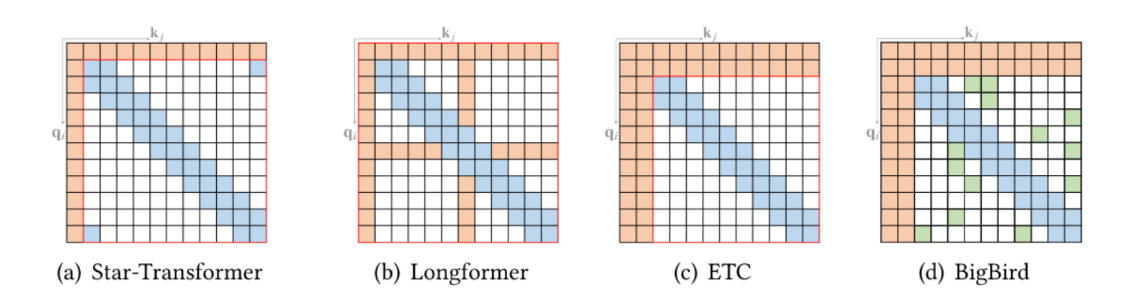
2.3.1.1 Star-Transformer
- 结构特点:星形拓扑结构。
- 局部连接:每个 Token 直接连接其相邻的 Token(环形/带状)。
- 中心中继:引入一个(或多个)中心节点(Relay Node)。所有 Token 都连接到中心节点,中心节点连接所有 Token。
- 信息传递:如果 Token A 想传信息给远处的 Token B,它先传给中心节点,再由中心节点传给 B(两跳即可到达)。
- 优势:结构轻量,避免过拟合,适合中小数据集。
2.3.1.2 Longformer
- 目标:专门为了处理长文档。
- 结构特点:Local + Global。
- Local Attention:使用滑动窗口(Sliding Window),每个词只看周围的词。
- Global Attention:在特定的任务相关位置(如分类标签位置 [CLS])使用全连接注意力。
- 效果:能够处理长达 4096 甚至更长的序列,复杂度随长度线性增长。
2.3.1.3 ETC
Encoding Long and Structured Inputs)
- 目标:处理长输入以及结构化文本。
- 结构特点:Global-Local Attention。
- 它定义了四种结构关系:Global-to-Global, Global-to-Local, Local-to-Local, Local-to-Global。
- 应用:通过显式地设计全局和局部的交互方式,更好地捕捉结构化数据的特征。
2.3.1.4 BigBird
- 目标:进一步降低二次方依赖,同时保证理论上的表达能力。
- 结构特点:Random + Window + Global 三合一。
- Window:保留局部邻居信息。
- Global:特定 Token 捕捉全局信息。
- Random:引入随机连接。
- 理论支撑:作者证明了加入随机连接后,BigBird 是图灵完备的(Universal Approximator),即在稀疏的情况下依然能模拟全连接的效果(基于小世界网络理论)。
2.3.1.5 压缩 Q, K, V
除了直接让注意力矩阵变稀疏(Masking),课件还提到了通过压缩维度来降低复杂度的方法:
- Informer:提出 Query Prototyping。认为 Query 分布是稀疏的,通过筛选出最具代表性的 Query(原型)来计算注意力,忽略其余的。
- Linformer:提出 Memory Compression。通过线性投影将 Key 和 Value 的序列长度投影到一个低维空间(比如从 $N$ 降到$k$),从而将$N\times N$ 的计算变成$N\times k$
2.3.2 架构层面改进
Transformer 在架构层面(Arch-level)的改进主要集中在以下五个关键组件和方向上。这些改进旨在解决原始 Transformer 训练难、位置信息僵化、计算冗余、以及层间交互不足的问题。
2.3.2.1 Position Embedding
原始 Transformer 使用固定的正弦/余弦函数进行绝对位置编码,但这并不总是最优解。
- 绝对位置编码 (Absolute):
- 原始:固定的函数编码(Vaswani et al., 2017)。
- 改进:可学习的位置嵌入(Learnable embeddings)(如 BERT),让模型自己学习位置的最佳表示。
- 相对位置编码 (Relative):
- 改进:Transformer-XL。不再给每个词一个绝对坐标,而是关注 Token 之间的距离(如“A在B前面第3个位置”)。这使得模型更能处理长序列,且具有平移不变性。
- 其他高级表示:
- Reformer:探索了旋转不变性等更复杂的几何关系。
- 隐式表示 (Implicit):
- R-Transformer:结合 RNN。
- 混合架构:在 Attention 后加入 CNN 或 RNN(如 CPT, CvT 等思路),利用卷积自带的局部坐标特性,直接去掉显式的位置编码。
2.3.2.2 Layer Normalization
这是让深层 Transformer 能够稳定训练的关键改动。
- Post-LN (原始设计):
- 位置:放在残差连接之后(Add & Norm)。
- 特点:性能上限可能更高,但极难收敛,需要配合复杂的 Warm-up 策略,训练初期梯度容易爆炸或消失。
- Pre-LN (改进设计):
- 位置:放在子层(Attention/FFN)之前。
- 特点:训练非常稳定,不需要 Warm-up 也能收敛。虽然有研究(如 Wang et al., 2022)指出其参数更新效率可能略低于 Post-LN,但因其稳定性,现在很多大模型(如 GPT-2/3)都采用 Pre-LN。
- 其他变体:
- PowerNorm:替换标准的 LayerNorm。
- ReZero:完全去掉 Norm 层,通过学习一个可训练的残差权重初始为 0,来实现深层网络的信号传播。
2.3.2.3 Feed Forward Network
FFN 占据了 Transformer 大部分的参数量,改进主要集中在激活函数和结构上。
- 激活函数:
- 从 ReLU 改进为 GELU (Gaussian Error Linear Unit)。GELU 更加平滑,在 BERT 和 GPT 中被广泛使用,能带来性能提升。
- 结构增强:
- 引入 Product-key memory 等机制来增加记忆容量。
- 极端简化:
- All-Attention:尝试完全丢弃 FFN,只保留 Attention 层。
2.3.2.4 Lightweight variants
针对标准 Transformer 计算量大、对局部特征提取效率低的问题。
- Lite Transformer:
- 问题:Self-Attention 算局部关系(Local relationship)太浪费(杀鸡用牛刀)。
- 方案:双分支结构。一个分支用 卷积 (CNN) 高效提取局部特征,另一个分支用 Attention 提取全局特征。
- **Funnel Transformer (漏斗 Transformer) **:
- 方案:像 CNN 的池化层一样,随着层数加深,逐渐压缩序列长度(Down-sample)。
- 效果:大大减少了中间层的计算量(FLOPs)和显存占用。
2.3.2.5 Inter-Block Connectivity
打破标准的“一层接一层”的堆叠模式,增强信息流动。
- Realformer:
- 残差注意力:不仅是层输出有残差,Attention 矩阵本身也可以有残差连接。即当前的 Attention Score 加上前一层的 Score,让注意力模式更连贯。
- Feedback Transformer:
- 反馈机制:允许高层(Upper layers)的抽象信息回传给低层(Lower layers),形成类似 RNN 的循环或层级反馈结构,增强语义理解。
架构层面的改进主要遵循三个逻辑:
- 好训练:Pre-LN, ReZero。
- 更灵活:相对位置编码, GELU。
- 更高效:Funnel Transformer, Lite Transformer。
3 Transformer in CV
Transformer 在计算机视觉(Computer Vision, CV)领域的演进并非一蹴而就,而是经历了一个**从“生搬硬套”到“融合视觉特性”再到“任务定制化”**的过程。
3.1 ViT
- 动机 (Motivation):Transformer 在 NLP 领域大杀四方,但在 CV 领域应用有限。能否直接用纯 Transformer 替代 CNN?
- 方法 (Method):
- Patch Partition:彻底抛弃卷积的归纳偏置,将二维图像切分为固定大小的块(例如 16x16 的 Patch)。
- Linear Projection:将每个 Patch 展平并映射为向量,直接视为 NLP 中的“单词”(Token)。
- 架构:直接使用标准的 Transformer Encoder,加上位置编码和一个用于分类的 Class Token。
- 局限性:
- 单尺度(Single-scale):ViT 输出的特征图分辨率始终不变(柱状结构),这对于分类够用,但对于需要精细空间信息的**密集预测任务(如检测、分割)**非常不利。
- 计算昂贵:全局注意力机制的复杂度是 $O(N^2)$,处理高分辨率图像时计算量爆炸。
3.2 PVT
为了解决 ViT 难以处理密集预测任务的问题,PVT 借鉴了 CNN 的设计哲学。
- 动机:ViT 的柱状结构无法生成多尺度特征(Multi-scale features),且计算量过大。
- 改进:
- 金字塔结构(Pyramid Structure):像 CNN(如 ResNet)一样,随着网络层数加深,逐渐减少 Token 的数量(下采样),形成多层级的特征图。这使得 PVT 可以作为通用的 Backbone 替换 CNN。
- 空间缩减注意力 (SRA):在计算 Attention 时,通过减少 Key 和 Value 的空间维度来降低计算和显存开销。
3.3 Swin Transformer
它解决了 ViT 的两个核心痛点:尺度变化和高分辨率下的计算瓶颈。
引入层级结构 (Hierarchical):
- Patch Merging:类似于 CNN 的池化(Pooling),将相邻的 Patch 合并,实现下采样。这让 Transformer 也能像 CNN 一样拥有层级特征。
窗口注意力 (Window-based Attention):
- 问题:全局 Attention 太慢。
- 方案:将图像划分为不重叠的局部窗口(Windows),只在窗口内部计算 Self-Attention。复杂度从 $O(N^2)$ 降为线性的 $O(N)$。
移动窗口 (Shifted Windows):
- 新问题:如果只在窗口内看,窗口之间就没有信息交流了,这就变成了孤岛,失去了 Transformer 捕捉全局信息的优势。
- 解决方案:在下一层移动窗口的位置(Shift)。这样,上一层属于不同窗口的像素,在这一层就会被同一个窗口覆盖,从而实现跨窗口的信息交互。
高效计算技巧 (Masked Attention):
- 工程挑战:移动窗口后,边缘的窗口大小不一(从 4 个变成了 9 个不同大小),难以并行计算。
- 巧妙解法:循环移位(Cyclic Shift) + 掩码(Mask)。将移出去的部分补到对面,凑成完整的窗口进行批量计算,再通过 Mask 屏蔽掉原本不相邻的区域(Slide 66)。
3.4 Other Application
当 Transformer 拥有了强大的特征提取能力后,研究者开始针对具体的 CV 任务改造其架构:
目标检测:DETR (Detection Transformer)
- 革命性:抛弃了 CNN 时代的 Anchor、NMS 等手工设计组件。
- 方法:将检测视为**集合预测(Set Prediction)**问题。
- 核心:使用 Transformer Encoder-Decoder 结构,通过**二分图匹配(Bipartite Matching)**直接输出预测框,实现了真正的端到端检测。
图像分割:Axial-DeepLab
- 方法:为了在降低计算量的同时保持长距离上下文,提出了轴向注意力(Axial Attention)。将昂贵的 2D Attention 分解为两个 1D Attention(先在高度方向做,再在宽度方向做)。
底层视觉(如超分):Texture Transformer
- 方法:利用 Self-Attention 的搜索能力,不仅仅利用局部信息,而是从参考图(Ref)中全局搜索相似的纹理特征来修复低分辨率图像。